syftr
Syftr helps businesses find the most effective and cost-efficient ways to use artificial intelligence for their specific needs. It explores different combinations of AI tools and settings to discover the best balance between accuracy and factors like cost and speed. This is particularly useful for companies building AI-powered applications, such as those using large language models for tasks like answering customer questions or summarizing documents. Data scientists and AI engineers can use Syftr to quickly identify optimal workflows without manually testing countless possibilities. Its unique approach allows users to see a range of potential solutions, showing the trade-offs between performance and budget, ultimately leading to smarter AI investments.
README
# <img src="https://raw.githubusercontent.com/datarobot/syftr/refs/heads/main/docs/syftr-logo.jpeg" alt="syftr Logo" width="200"/> Efficient Search for Pareto-optimal Flows
__syftr__ is an agent optimizer that helps you find the best agentic workflows for a given budget. You bring your own dataset, compose the search space from models and components, and __syftr__ finds the best combination of parameters for your budget. It uses advances in multi-objective Bayesian Optimization and a novel domain-specific "Pareto Pruner" to efficiently sample a search space of agentic and non-agentic flows to estimate a Pareto-frontier (optimal trade-off curve) between accuracy and objectives that compete like cost, latency, throughput.
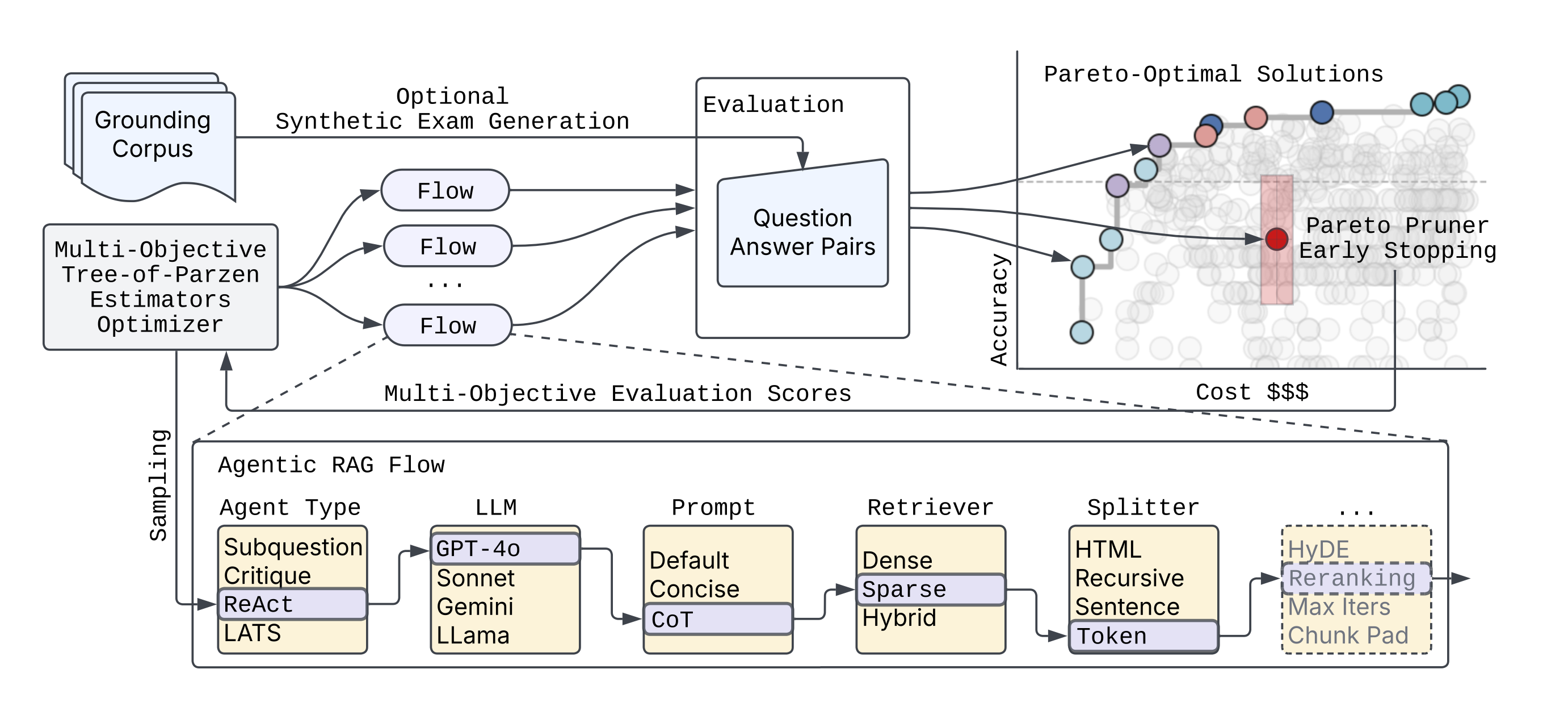
Please read more details in our [blogpost](https://www.datarobot.com/blog/pareto-optimized-ai-workflows-syftr)
and full [technical paper](https://arxiv.org/abs/2505.20266).
We are excited for what you will discover using __syftr__!
## Libraries and frameworks used
__syftr__ builds on a number of powerful open source projects:
* [Ray](https://www.ray.io/#why-ray) for distributing and scaling search over large clusters of CPUs and GPUs
* [Optuna](https://optuna.org/) for its flexible define-by-run interface (similar to PyTorch’s eager execution) and support for state-of-the-art multi-objective optimization algorithms
* [LlamaIndex](https://www.llamaindex.ai/) for building sophisticated agentic and non-agentic RAG workflows
* [HuggingFace Datasets](https://huggingface.co/docs/datasets/en/index) for fast, collaborative, and uniform dataset interface
* [Trace](https://github.com/microsoft/Trace) for optimizing textual components within workflows, such as prompts
## Installation
Please clone the __syftr__ repo and run:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv --python 3.12.7
source .venv/bin/activate
uv sync --extra dev
uv pip install -e .
```
or to use syftr as a library, install directly from PyPi:
```bash
pip install syftr
```
NOTE: __syftr__ works as a library, but still needs easy access to `config.yaml` and study files you intend to run. Config file should be present as `~/.syftr/config.yaml`, or in your current working directory.
You can download sample config file to your `~/.syftr` directory with this command
```bash
curl -L https://raw.githubusercontent.com/datarobot/syftr/main/config.yaml.sample \
-o ~/.syftr/config.yaml
```
You also need studies to run __syftr__. You can write your own or download our example study with this command to current working directory
```bash
curl -L https://raw.githubusercontent.com/datarobot/syftr/main/studies/example-dr-docs.yaml > example-dr-docs.yaml
```
### Required Credentials
__syftr__'s examples require the following credentials:
* Azure OpenAI API key
* Azure OpenAI endpoint URL (`api_url`)
* PostgreSQL server dsn (if no dsn is provided, will use local SQLite)
To enter these credentials, copy [config.yaml.sample](https://github.com/datarobot/syftr/blob/main/config.yaml.sample) to `config.yaml` and edit the required portions.
## Additional Configuration Options
__syftr__ uses many components including Ray for job scheduling and PostgreSQL for storing results. In this section we describe how to configure them to run __syftr__ successfully.
* The main config file of __syftr__ is `config.yaml`. You can specify paths, logging, database and Ray parameters and many others. For detailed instructions and examples, please refer to [config.yaml.sample](https://github.com/datarobot/syftr/blob/main/config.yaml.sample).
You can rename this file to `config.yaml` and fill in all necessary details according to your infrastructure.
* You can also configure __syftr__ with environment variables: `export SYFTR_PATHS__ROOT_DIR=/foo/bar`
* When the configuration is correct, you should be able to run [`examples/1-welcome.ipynb`](https://github.com/datarobot/syftr/blob/main/examples/1-welcome.ipynb) without any problems.
* __syftr__ uses SQLite by default for Optuna storage. The `database.dsn` configuration field can be used to configure any Optuna-supported relational database storage. We recommend Postgres for distributed workloads.
## Quickstart
First, run `syftr check` to validate your credentials and configuration.
Note that most LLM connections are likely to fail if you have not provided configuration for them.
Next, try the example Jupyter notebooks located in the [`examples`](https://github.com/datarobot/syftr/blob/main/examples) directory.
Or directly run a __syftr__ study using the CLI `syftr run studies/example-dr-docs.yaml --follow` or with the API:
```python
from syftr import api
s = api.Study.from_file("studies/example-dr-docs.yaml")
s.run()
```
Obtaining the results after the study is complete:
```python
s.wait_for_completion()
print(s.pareto_flows)
[{'metrics': {'accuracy': 0.7, 'llm_cost_mean': 0.000258675},
'params': {'response_synthesizer_llm': 'gpt-4o-mini',
'rag_mode': 'no_rag',
'template_name': 'default',
'enforce_full_evaluation': True}},
...
]
```
## LLM Configuration
__syftr__ can be configured to use a wide variety of LLMs from a variety of LLM providers.
These are configured using the ``generative_models`` section of ``config.yaml``.
Each LLM provider has some different configuration options as well as some common ones.
Let's look at an example using ``gpt-4.5-preview`` hosted in Azure OpenAI:
```yaml
generative_models:
# azure_openai Provider Example
azure_gpt_45_preview:
provider: azure_openai
temperature: 0.0
max_retries: 0
# Provider-specific configurations
deployment_name: "gpt-4.5-preview"
api_version: "2024-12-01-preview"
additional_kwargs:
user: syftr
# Cost example - options are the same for all models (required)
cost:
type: tokens # tokens, characters, or hourly
input: 75
output: 150.00
# rate: 12.00
# LLamaIndex LLMetadata Example - keys and defaults are the same for all models
metadata:
model_name: gpt-4.5-preview
context_window: 100000
num_output: 2048
is_chat_model: true
is_function_calling_model: true
system_role: SYSTEM
```
### Provider-specific options
All LLM configurations defined under `generative_models:` share a common set of options inherited from the base `LLMConfig`:
* **`cost`**: (Object, Required) Defines the cost structure for the LLM.
* `type`: (String, Required) Type of cost calculation: `tokens`, `characters`, or `hourly`.
* `input`: (Float, Required) Cost for input (e.g., per million tokens/characters).
* `output`: (Float, Required if `type` is `tokens` or `characters`) Cost for output.
* `rate`: (Float, Required if `type` is `hourly`) Average cost per hour.
* **`metadata`**: (Object, Required) Contains essential metadata about the LLM.
* `model_name`: (String, Required) The specific model identifier (e.g., "gpt-4o-mini", "gemini-1.5-pro-001").
* `context_window`: (Integer, Optional) The maximum context window size. Defaults to `3900`.
* `num_output`: (Integer, Optional) Default number of output tokens the model is expected to generate. Defaults to `256`.
* `is_chat_model`: (Boolean, Optional) Indicates if the model is a chat-based model. Defaults to `false`.
* `is_function_calling_model`: (Boolean, Optional) Indicates if the model supports function calling. Defaults to `false`.
* `system_role`: (String, Optional) The expected role name for system prompts (e.g., `SYSTEM`, `USER`). Defaults to `SYSTEM`.
* **`temperature`**: (Float, Optional) The sampling temperature for generation. Defaults to `0.0`.
See [LLM provider-specific configuration](https://github.com/datarobot/syftr/blob/main/docs/llm-providers.md) to configure each supported provider.
### Embedding models
You may also enable additional embeddi
[truncated…]PUBLIC HISTORY
IDENTITY
Identity inferred from code signals. No PROVENANCE.yml found.
Is this yours? Claim it →METADATA
README BADGE
Add to your README:
